正确使用分布式锁
Table of Contents
单机环境做资源互斥比较简单,内核提供的 mutex、信号量这些机制,本质上依赖的是同一台机器上共享内存的可见性。所有线程都能看到同一块内存,CAS 一条指令就能完成状态判断和更新,原子性由硬件保证。
到了分布式环境,事情变得麻烦了。不同机器之间没有共享内存,无法实现原子操作。我们需要一个第三方服务来判断谁能拿到锁,这就是分布式锁的出发点。
严格互斥性
分布式锁最核心的承诺是:同一时刻,只有一个 client 能持有这把锁。
大多数实现(比如 etcd、ZooKeeper)采用的都是 lease 机制。服务端把每把锁和一个 session 绑定,client 拿到锁之后,需要定期发送心跳来 refresh lease。心跳断了,lease 到期,服务端自动释放锁,其他 client 才有机会抢占。
关键点:
- 客户端先于服务端发现锁过期
- client 维护一个比 lease TTL 更短的计时器,更早停止对共享资源的操作,减少网络问题造成的「临界区重叠」
- 客户端抢到锁后,等一个心跳周期再开始干活
- 给持有锁的 client 留出足够的窗口停止对共享资源的操作
即使做了这两点优化,分布式锁本身仍然做不到绝对互斥。
Martin Kleppmann 在 2016 年那篇著名的文章里画过一个时序图:
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
- client1 持有锁,GC 暂停期间 lease 过期
- client2 抢到锁并开始写资源
- GC 结束后 client1 恢复执行,也写资源,数据被破坏了。
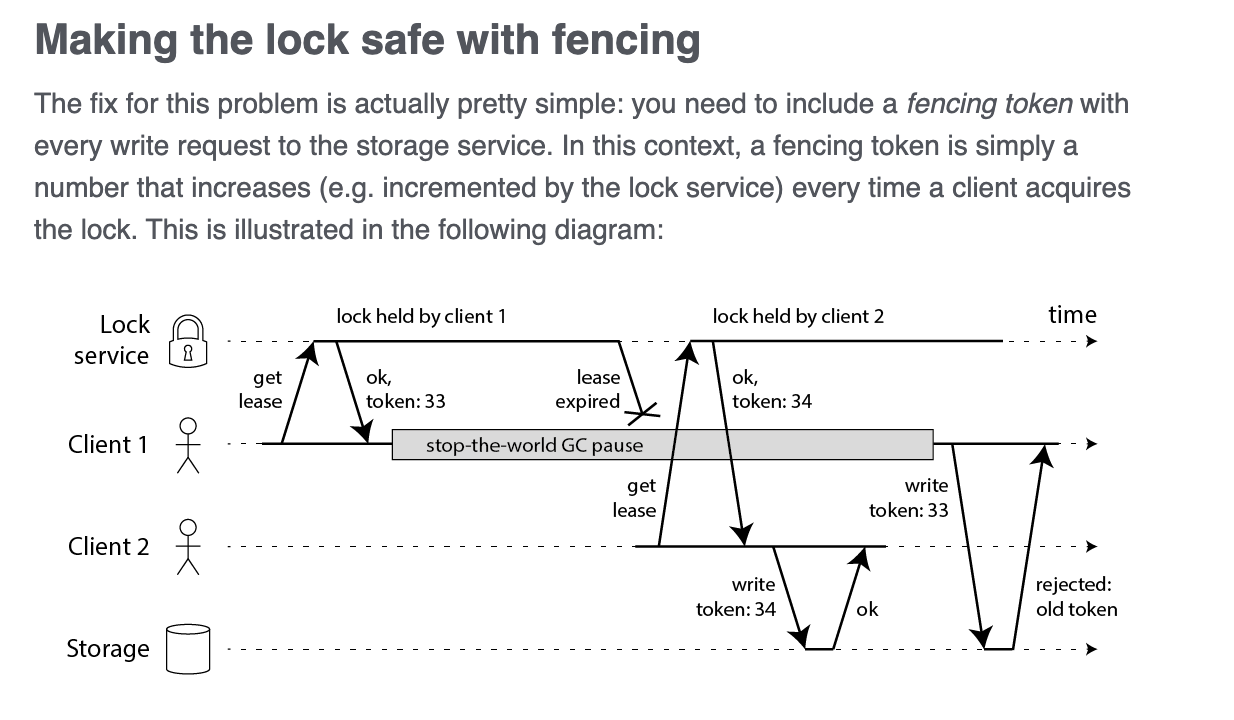
要真正解决这个问题,只靠分布式锁是不行的,依赖存储层提供 fencing 能力。思路很简单:每次写操作带一个单调递增的 token,存储层只接受 token 最大的那次写入。
常见做法:
- 利用 etcd 的 revision 做 CAS 比较,写入时带上预期的 revision,不匹配就拒绝
- 数据库 update 语句的 where 条件带上版本号
- 分布式文件系统提供 seal file + meta CAS 的能力
分布式锁负责协调竞争,fencing 负责保证写操作的正确性。如果要实现严格的互斥性,两者缺一不可。
可用性
- lease 的时长设置影响服务可用性
- 正常流程:client 完成任务后主动 revoke lease,锁立刻释放,其他 client 抢锁
- 异常场景(进程 crash、机器宕机、网络分区):client 没机会主动释放锁,只能干等 lease 超时,其他 client 才能抢锁,期间服务不可用
- 服务发现场景:lease 的时长 30s,每 1/3 TTL 续约,是实践中的推荐值
- 高 Load 导致的进程假死,lease 心跳还在保持,但是 worker 线程不工作,如何释放锁?
- 停进程
- 加黑 session 心跳,让 lease 自动过期释放,优雅安全
- 如果是锁的「非持有者」删除锁点,原持有者因为各种原因未放锁,可能破坏锁的互斥性,不建议
其他
多个 client 同时抢同一把锁的时候,如果所有人都轮询同一个 key,锁一释放容易产生惊群,对服务端压力比较大。etcd 的做法是每个 client 创建带序号的 key 之后,只去 watch 排在自己前面的 key 的删除操作,排队抢锁。