Git 高可用探讨
Table of Contents
如果你比较熟悉 KV 存储,那么在做 Git 的高可用方案设计时很容易把 KV 的方案往里套,即 oplog 中记录文件的内容和 Create/Delete/Update 操作,其他节点通过 replay log 来恢复 Git 仓库数据。很不幸,你会发现不同副本间的 commit 不一致 —— 即使在 oplog 中存储了 commit 的 date,这也是一个脆弱的保证。
oplog 关注的是 数据层面确定性的物理变更,上面这种方案类比到 KV 存储里就像把 语义 API 写到了 oplog 中,本质上是没有理解 Git 的底层存储原理,.git/ 才是 "数据层面确定性的物理变更"。
Git 的特性
Git 是基于内容寻址的键值系统, .git/ 目录下是真正的数据。我们主要关注目录下的 objects 和 refs。
objects
对象分为以下几种类型:
- commit
- 存储 commit 信息,包含 author、date、message
- tree
- 存储某个目录下的信息
- blob
- 存储文件内容
对象以 key-value 的形式管理,key 是对象内容的 hash,value 是 zlib 压缩后的对象内容,可使用 git cat-file -p 查看某个对象的内容。
对象在磁盘上有两种存储格式:
- 松散对象 (loose objects)
- 打包文件(packfile)
当松散对象超过 6700 或者 打包文件超过 50 个时(默认值)并开启了 gc.auto,执行 git 命令会触发 gc。
refs
refs 目录存储 git 的引用,包括 branch、tag、remote ref,以及一些自定义 namespace 的分支。
refs 也按照 key-value 的形式管理。key 是 ref 的名字,比如 refs/heads/master,value 可以是 hash 也可以指向另一个 ref(Symbolic Reference),类似文件系统中的软链。
refs 在磁盘上也有两种存储格式:
- loose refs
- refs/ 目录下每个文件存储一个 reference
- packed refs
- 存储在 packed-refs 文件中,每行代表一个 reference
git smart http
git 使用 git clone/fetch同步仓库数据,实际是一套自定义的 pkt-line 有状态的传输协议,称之为 git smart http。
主要分为三个阶段:
- 引用发现
- server 返回 refs 列表和 hash
- Packfile 协商
- server 根据 client 提供的 refs haves、wants 列表,计算出来最小的 packfile
- 数据传输
- server 将 packfile 数据发送给 client
再结合上面的分析,不难发现,如果我们能保证
- refs 的一致性
- 能够引用到的对象都是存在的
是可以保证 git repo 的数据一致性的。注意: objects 无需保证一致性,允许出现悬空对象,各个节点可以在 gc 时自行清理。
分布式文件系统的美好想象
Git 是基于本地文件系统的,如果能把本地文件系统替换为分布式文件系统,不就解决了高可用和存储上限的难题了吗? 尤其是 go-git/libgit2 还提供了 Storage 的 interface 可替换 backend。我可真是个天才。
两盆冷水泼下来。
Gitee 早期尝试过 Ceph 的方案,仓促上线后海量小文件的遍历 IO 性能惨不忍睹,后来又回退到主备架构。
阿里早期也做过类似的尝试,将 libgit2 的后端嫁接到 oss, 有同事在 RailsConf 2016 中做了 专题分享
- oss 替换掉 odb,存储 commit、tree、blob 对象。refdb 存储 refs 等指针信息
- oss bucket 分为 loose 和 pack 两种 ,用户如果上传的 pack 太大,就调用
git-index-pack生成 idx,读的时候利用 http get 的 range header 先读 idx 拿到 pack 的数据范围,递归解析 base 直到 root 对象。
最终也因为性能问题和越来越无法收敛的底层改动成本放弃。
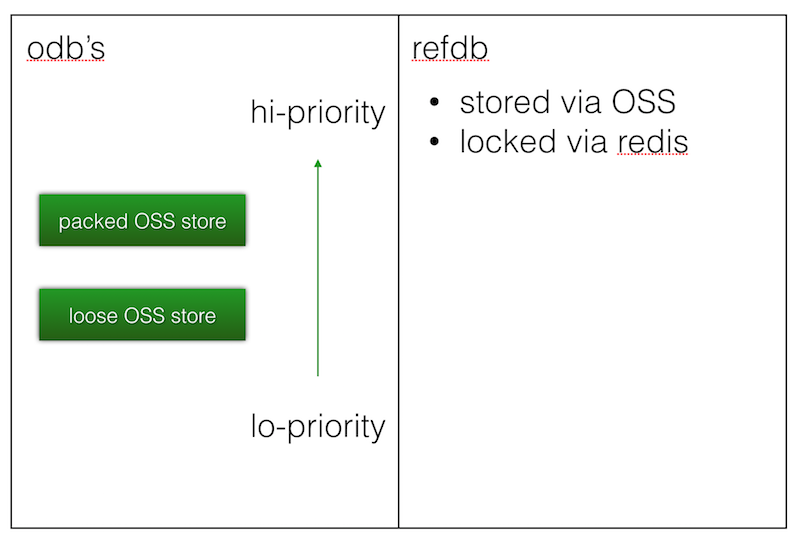
目前业界基本达成了共识,git loose object 大量小文件、随机访问的特点,恰恰是分布式文件系统的弱项。
主从同步 + 读写分离
以 Gitee 为例, 路由分片,不同用户的仓库分布在不同的机器上。这里应该用仓库的 ID 做分片键,而不是依赖于仓库路径(可能变化)。
大概的流程:
- 写请求路由到主节点
- 主节点完成 Git 操作(更新 objects + refs),通过 Git 钩子触发一个同步队列
- 备节点消费任务,执行 git fetch 或自定义协议拉取数据,至少一个备机同步成功才算写成功
- 校验 refs 的 checksum,确认一致性,管理变更同步状态,从节点可读
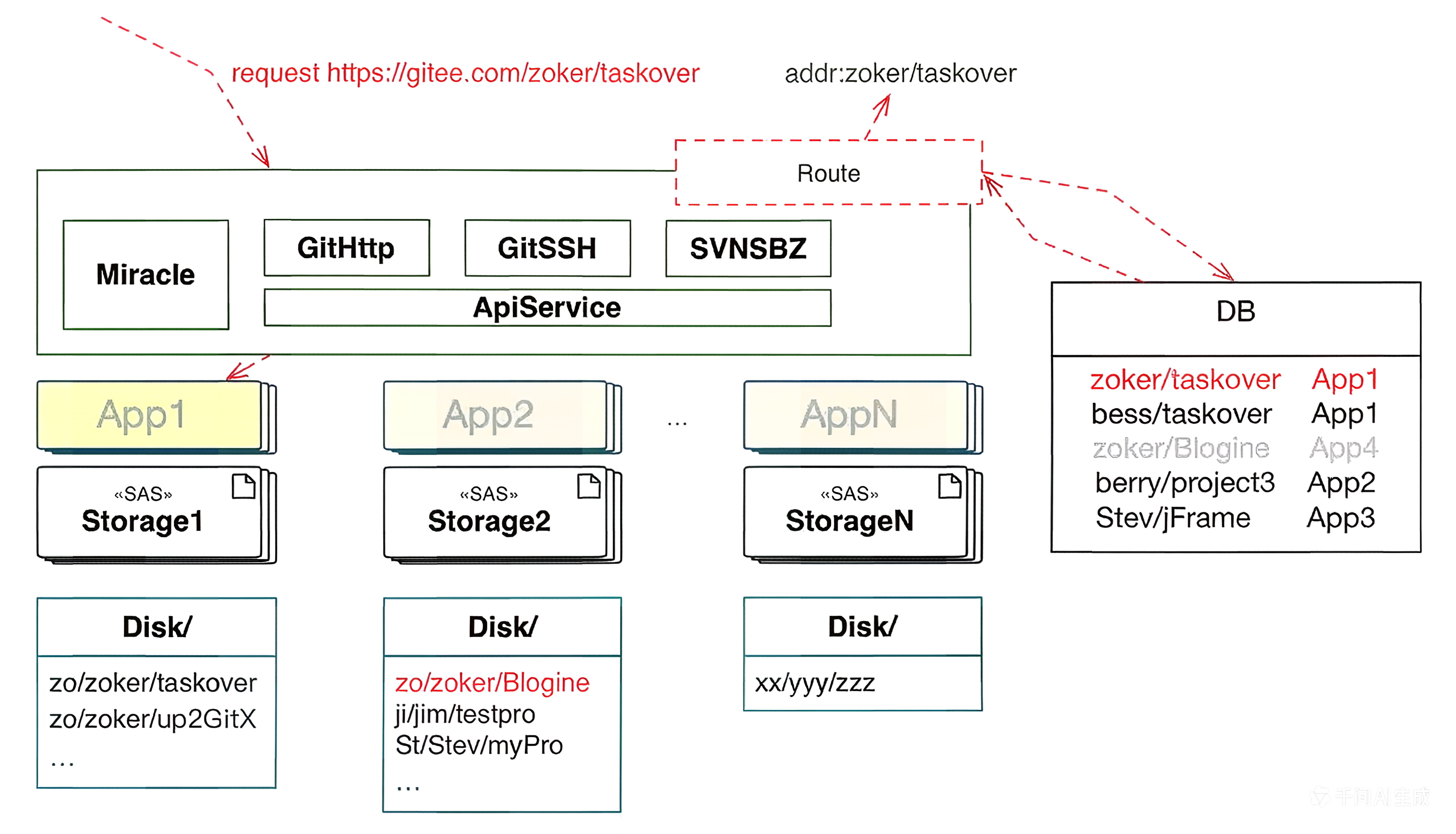
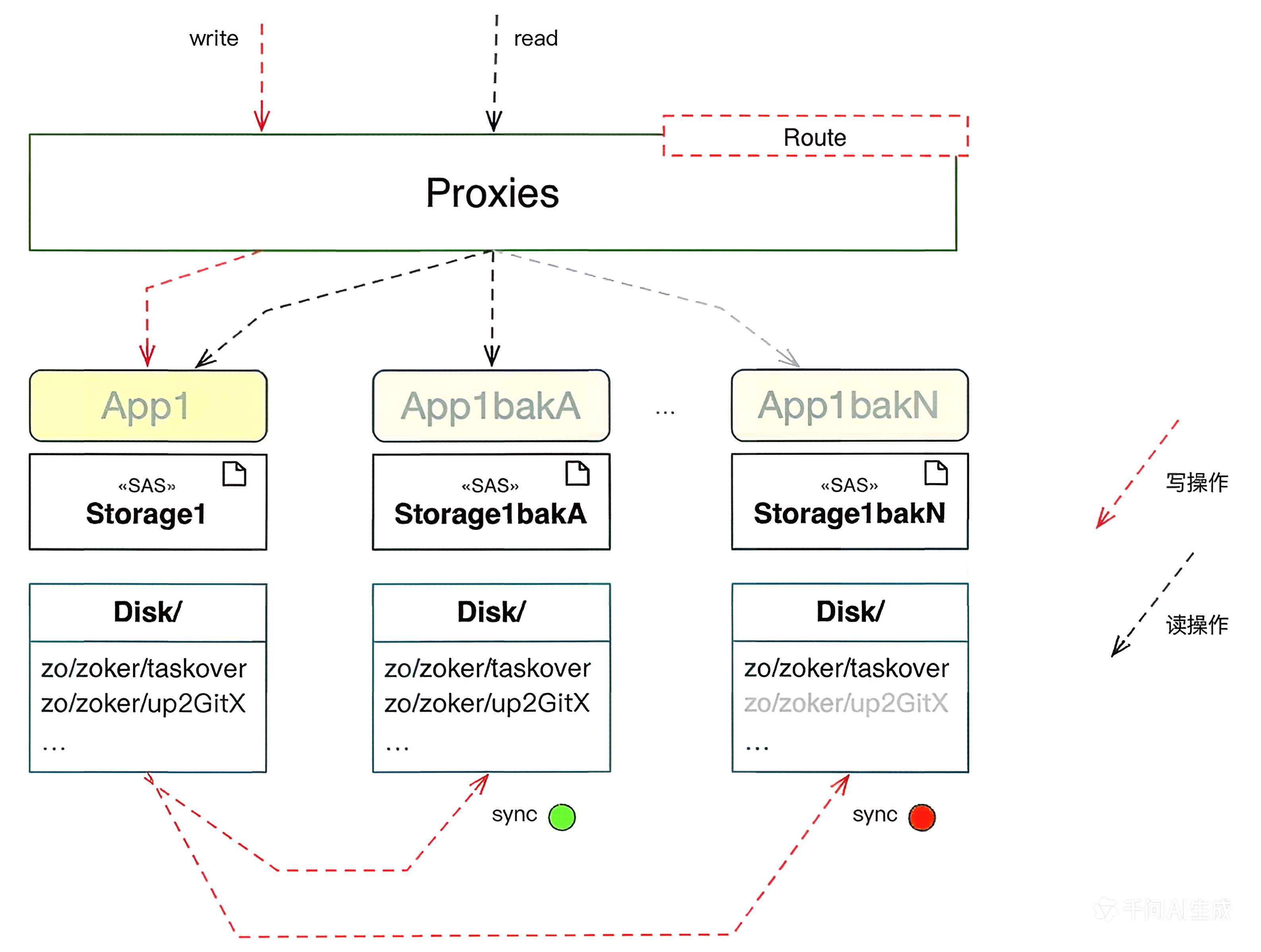
主从架构简单可靠,足以满足大部分的业务场景。但也有缺点:
- 同步写增加了写操作的延迟
- 如果写 QPS 非常高,备节点一直在同步数据,会回退到单节点读写的形态
多写高可用
阿里云的 Codeup 采用了一种更激进的方案:多写高可用。
大概的流程:
- 使用仓库 ID 作为存储和分片的基本单位
- 通过 gRPC 将写请求分发到多个副本
- 同步写三副本,多数节点写成功即返回成功
- 写失败或数据不一致通过 refs 的 checksum 校验发现
- 更新路由层,避免读到问题数据
这个方案的优势:任意节点都可以处理写请求,没有单点瓶颈。
我觉得这里是有 corner case 的。考虑如下场景:
- 三个并发请求 r1、r2、r3 同时写入同一个仓库
- 三个副本节点 A、B、C
- 由于分布式系统的网络延迟不可控,可能出现:
- A 节点:r1 成功
- B 节点:r2 成功
- C 节点:r3 成功
结果是三副本的 refs 都不一致,checksum 全部对不上。这种场景下,系统无法自动判断哪个是正确的,只能人工介入处理。
好消息是:Git 仓库的写 QPS 通常不会很高(不像 KV 存储),内网环境网络延迟也相对可控,这种极端并发冲突的概率较低。
多副本同步
再结合上面对 objects 和 refs 的分析,不难发现,如果我们能保证
- refs 的一致性
- 能够引用到的对象都是存在的
通过 etcd/raft 来保证各节点上 refs 的一致性,raft 同步日志时将 packfile 传输给其他节点。
raft 框架中需要做的操作:
- Apply:保存 packfile 到本地的 git 仓库,并更新 refs
- SaveSnapshot:raft 只会维护 refdb,同步 refdb 到其他节点,节点再通过 git fetch 拉取 objects
不再展开。
完全抛弃 git 的大库存储方案
前面的方案都是在「兼容 Git 协议」的前提下做高可用。
蚂蚁的 HugeSCM 是一个大胆的尝试。它保留了 Git 的用户体验(commit、branch、merge),但完全重写了底层存储。
HugeSCM 的核心创新在于数据分离原则,将版本控制系统的数据分为两类:
元数据(Metadata)
包括提交对象(commit)、目录对象(tree)、分片对象(fragments)和标签对象(tag)。这些对象体积较小,但访问频繁,适合存储在分布式数据库中,支持快速索引和查询。
文件数据(Blob)
文件内容数据,体积可能非常大,存储在分布式文件系统或对象存储中。Blob 采用压缩存储,支持多种压缩算法(ZSTD、Brotli、Deflate 等)。
这种分离设计带来了显著优势:
+------------------+ +------------------+
| 元数据数据库 | | 对象存储/OSS |
| (分布式数据库) | | (分布式文件系统) |
+------------------+ +------------------+
↑ ↑
│ │
commit/tree blob 数据
fragments/tag (压缩存储)
(高频访问) (大文件优化)
https://github.com/antgroup/hugescm/blob/master/docs/design.md
我觉得是一种不错的尝试,尤其是现代 AI 模型训练产生的 checkpoint 文件动辄数十 GB 甚至上百 GB,一个存储库可能包含多个版本,总体积轻易突破 TB 级别。Git LFS 虽然缓解了这一问题,但引入了额外的存储开销和管理复杂度,仍属于一种「外挂」机制。
Git 协议既是利刃也是枷锁,这或许就是技术发展的宿命:每一次进化,都是对过往荣光的告别与超越。